JeŇľeli do oprogramowania inŇľynierskiego moŇľna podpińÖńá wŇāasne procedury to NVIDIA udostńôpnia darmowy driver NVCC za pomocńÖ kt√≥rego moŇľna kompilowańá kod napisany w C. MoŇľna to robińá z Visual Studio (od wersji 10) pod Windows lub uŇľywajńÖc gcc pod Linuxem.
W√≥wczas oprogramowanie optymalizuje sińô pod posiadanńÖ kartńô graficznńÖ. Warto mieńá kartńô o CUDA capability wińôkszym niŇľ 2.0 ze wzglńôdu na obsŇāugńô typu double.Zobacz Komentarze News√≥w
Czy ktoŇõ z forum korzysta moŇľe z Elmera? Bardzo ciekawi mnie jak to dziaŇāa. Bo z tego tutka wynika, Ňľe jest OK, a tymczasem ja pr√≥bowaŇāem... bezskutecznieZobacz Komentarze News√≥w
High-performance computing (HPC) is a crucial tool for all levels of automotive design and manufacturing. It is used for computer-aided engineering (CAE) from the component level to full vehicle analyses: crash simulations, structural integrity, thermal management, climate control, engine modeling, exhaust, acoustics, and more. HPC helps drive faster times to market, cost reductions, and design flexibility. The advantage of HPC is the ability to achieve sustained performance by driving CPU performance toward its limit.
The motivation for HPC in the automotive industry has long been its tremendous cost savings and product improvements. The total cost of a single real vehicle crash test to determine safety characteristics is in the range of $250,000 or more. On the other hand, the cost of a high-performance compute cluster can be just a fraction of the price of a single crash test, while providing a system that can be used for every test simulation going forward.
Complex automotive crash simulations demand the use of HPC clusters to enable true virtual development, especially virtual prototypes, with the aim of assuring that expensive physical prototypes are only used for simulation verification.
Complex automotive crash simulations demand the use of HPC clusters to enable true virtual development, especially virtual prototypes, with the aim of assuring that expensive physical prototypes are only used for simulation verification.
In addition to crash simulations, compute-intensive systems and applications can simulate everything from airbag deployment to brake cooling and from thermal comfort to windshield-washer nozzles. HPC-based simulations and analyses empower engineers and designers to create vehicles ultimately better equipped for todayr17;s real-life environments.
HPC for Crash Simulations
Figure 1: This chart illustrates the performance
gains in using InfiniBand versus GigE during an
LS-DYNA benchmark test over multiple cores.
Crash simulations, however, are one of the most demanding aspects of automotive design. Whether exploring full-frontal, offset-frontal, angle-frontal, side-impact, rear-impact, or others, crash simulations are becoming more sophisticated and numerous as more parts and details can be analyzed. Their complexity demands the use of HPC clusters r12; off-the-shelf servers, a high-speed interconnect, and adequate storage r12; to realize the vision of pure virtual development so expensive physical prototypes are only used for simulation verification.
HPC clusters have helped Volvo, for example, perform complex crash simulations; the flexibility and scalability of HPC clusters enabled the car company to increase computation power to perform greater numbers of simulations while speeding autos to market. Volvo performed 1,000 simulations and used 15 prototypes during the design of its S80 from 1993-1998. It increased simulations to 6,000 and used only five prototypes for the S40/V40 series (1999-2003), and performed 10,000 crash simulations during development of its V70N model (2005-2007) without destroying any real prototypes. These are crash simulations that included a large variety of landscapes, such as pedestrian, slide impact, rollover, and many others.
Multicore cluster environments
Compute cluster solutions consist of multicore servers that introduce high demands on cluster components, especially with regard to cluster connectivity. Each CPU core imposes a separate demand on the network during simulations, which means the cluster interconnect needs to be able to handle those multiple data streams simultaneously while guaranteeing fast and reliable data transfer for each stream.
In a multicore environment, it is essential to avoid overhead processing in the CPU cores. InfiniBand provides low latency, high bandwidth, and extremely low CPU overhead; it provides a balanced compute system and maximizes application performance, which is a big reason why InfiniBand is emerging as a widely deployed high-speed interconnect, replacing proprietary or low-performance solutions.
SMP Versus MPI
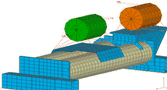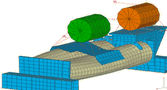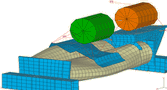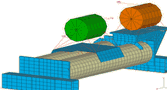
Figure 2: This illustration of the two methods examined shows a single-job approach vs. parallel jobs.
A common multicore environment consists of 8 to 16 CPU cores in a single server. In a typical single-server environment, jobs can be executed in a shared memory processing (SMP) fashion, or with a message passing interface (MPI) protocol. To determine which of the two is most efficient and productive, we compared the two options using Livermore Software Technology Corporation (LSTC) LS-DYNA benchmarks.
LS-DYNA is a general-purpose structural and fluid analysis simulation software package capable of simulating complex real world problems. It is widely used in the automotive, aerospace, and consumer products industries. There are three main LS-DYNA benchmarks used for evaluating a platformr17;s performance, efficiency, and scalabilityz:
r6; Three-vehicle collision: a van crashes into the rear of a compact car, which, in turn, crashes into a midsize car
r6; Neon refined: frontal crash with initial speed at 31.5 mph (a revised version called Neon Refined Revised) was recently introduced
r6; Car2car: NCAC minivan model.
We used the Mellanox Technologies Helios cluster for this performance evaluation. It is part of the Mellanox Cluster Center, a compute resource available for performance testing and application development. The Helios cluster consists of 32 server nodes, connected with gigabit Ethernet and 20Gbps InfiniBand. Each server node has dual-socket, Quad-core 2.66GHz Intel Xeon CPUs (code name Clovertown). The MPI used in the test was Scalir17;s MPI Connect.
Our comparison metric was the number of jobs that can be completed in 24 hours. We found that the use of MPI improves the systemr17;s efficiency and parallel scalability and, as more cores were used, we found the MPI approach worked more efficiently than the traditional SMP way.
Scaling to cluster environment: the importance of interconnects
This is an illustration of how socket affinity is approached during testing.
The way the cluster nodes are connected together has a great influence on the overall application performance, especially when multicore servers are used. The cluster interconnect is critical to efficiency and scalability of the entire cluster, as it needs to handle the I/O requirements from each of the CPU cores, while not imposing any networking overhead on the same CPUs.
Figure 1 compares gigabit Ethernet and 10Gbps InfiniBand as an interconnect solution. The cluster consisted of dual-socket, dual-core Intel Xeon CPUs (Woodcrest) server nodes. For up to 16 cores (four compute nodes), InfiniBand performed more efficiently than GigE, enabling up to 25 percent more LS-DYNA jobs per day. When scaling up to 32 cores, or eight server nodes, GigE failed to provide an increase in number of jobs, while also diminishing the overall compute power. InfiniBand continued to provide almost linear scalability and high efficiency by nearly doubling the number of LS-DYNA crash simulations achieved per day.
More Simulations on InfiniBand Cluster
Thus, for multicore cluster platforms, GigE becomes ineffective with cluster size and InfiniBand is required in order to maximize the application performance and the number of jobs that can be completed per day.
Typically, the faster the run time, the more effective the compute solution. However, this is not always the best approach for real simulation on multicore platforms. Multicore platforms place more demand on the cluster interconnect, on the CPU connectivity within a server node, and between the CPUs and memory. Though running a single job on the cluster will provide the fastest times for that specific job, the goal of maximum simulations per day might not be achieved in this manner.
Figure 3: LS-DYNA jobs per day demonstrated with and without socket affinity.
Figure 2 shows the two different methods that were examined. The platform used for this testing is the Helios cluster from the Mellanox Cluster Center, using the Scali MPI Connect. Each node consists of dual socket, quad-core CPUs. One method (left side) is to run a job on the entire compute cluster and launch the second job once the first job is completed. The second method (right side) is to run two jobs in parallel, with each using only one socket per node and placing higher demands on the cluster interconnect.
Figure 3 shows the performance results of the two options. Although the run time of a single job on the entire cluster is faster, running multiple jobs at the same time using InfiniBand to connect between the servers provides more than two times LS-DYNA jobs per day.
Accelerating Automotive Design
In the first case we examined for our evaluation, it was clear that using applications over MPI will provide more performance (versus using an SMP mode) even on a single server.
In the second case, we investigated the importance of using high-speed, low-latency, and low-CPU overhead interconnects for crash simulations. According to our results, a low-speed interconnect, such as GigE, becomes ineffective with cluster size and even reduces the cluster compute power when adding more compute nodes. InfiniBand shows greater efficiency and scalability with cluster size.
The third case shows that CPU affinity and interconnect use needs to be configured correctly to maximize cluster efficiency. By reducing the stress on socket connectivity and memory, while making better use of the interconnect, more jobs can be accomplished, enabling more complex simulations, thereby improving design phase efficiency and reducing physical prototypes considerably.
More Information:
Mellanox Technologies
Santa Clara, CA
mellanox.com
http://www.deskeng.com
Pozdrawiam,
Admin
We live in an age when pizza gets to your home faster than police or an ambulance
Skocz do Forum:
Reklama
Szukaj
Logowanie
Nie jesteŇõ jeszcze naszym UŇľytkownikiem? Kilknij TUTAJ Ňľeby sińô zarejestrowańá.
Tylko zalogowani mogńÖ dodawańá posty w shoutboksie.
Bulix 26.01.2022 Witam, szukam osoby która ogarnia program FEMM.
damian14100 25.01.2022 Witam,
Czy znajduje sińô na forum osoba kt√≥ra ma doŇõwiadczenie w obliczeniach wytrzymaŇāoŇõciowych w√≥zk√≥w wagonowych ?
BE-FEA 31.03.2021 Nie pracujńô w Deform, ale moŇľe coŇõ podpowiem na zasadzie analogii do innych program√≥w MES. Napisz jeŇõli nadal aktualne.
daniel8894 31.03.2021 Czy pom√≥gŇāby ktoŇõ w zrobieniu symulacji procesu skrawania w Deform 3 d
BE-FEA 09.03.2021 Postaram sińô pom√≥c, zapraszam do kontaktu jeŇõli nadal aktualne.
kinia22 09.03.2021 witam, potrzebuje kogoŇõ kto pomoŇľe w przygotowaniu projektu w programie COMSOL - przeplyw ciepŇāa przez oŇõrodek porowaty!
BE-FEA 02.04.2020 PrzerobiŇāo mi jednńÖ literńô na emotkńô. Chodzi o przycisk new thread
BE-FEA 02.04.2020 ŇĽeby dodańá nowy temat wystarczy wejŇõńá w odpowiedni dziaŇā i kliknńÖńá maŇāy przycisk "ew thread" po prawej stronie.
KrzywaOHIO 30.03.2020 Jak dodańá nowy wńÖtek na forum?
Konrad96 02.12.2019 Witam, czy jest tu ktoŇõ kto dobrze zna sińô na programie Robot struktural i pom√≥gŇāby mi zamodelowańá belkńô ŇľelbetowńÖ podobnńÖ do belki uŇľytej w badaniu? Proszńô o kontakt jeŇõli ktoŇõ chciaŇāby pom√≥c



 UŇľytkownicy Online
UŇľytkownicy Online








 ew thread" po prawej stronie.
ew thread" po prawej stronie.


